Tokenization in natural language processing.
What is tokenization?
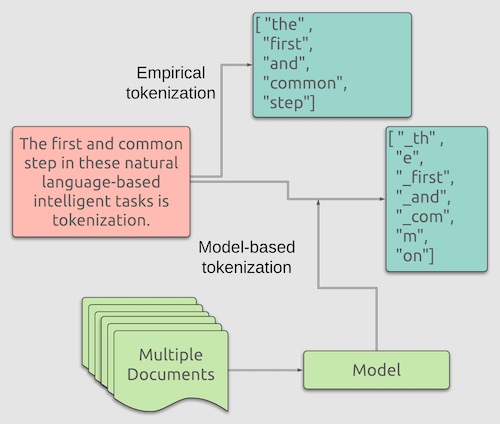
A typical NLP task involves going through text data, understanding context, and performing intellectual activities that humans typically perform. Such higher-level tasks include understanding emotions, paraphrasing, summarization, identifying keywords, etc. The first and common step in these natural language-based intelligent tasks is tokenization. Tokenization divides a phrase, sentence, paragraph, or an entire text into smaller units as individual words or terms. Each of these building blocks of text is known as a token. A token can be a word, part of a word, or just plain characters like punctuation.
The tokens and order in which they occur give meaning to the text. For comprehension by humans, the sentence should be composed of tokens from a dictionary (or provided by naming authorities) and in an order determined formal grammar. However, for use in machines or computers, the tokens can be arbitrary fragments of text.
Empirical tokenization:
Tokenizers that break text into tokens using space as a delimiter is sufficient to produce vocabulary for language like English. Space delimited tokenization is the most preferred tokenization method for word-vector-based NLP workflows. While simplicity, speed, and easy implementation are the main advantages, downstream NLP tasks may have to work with an extensive vocabulary. Often the simple tokenization using space as a delimiter is extended to include punctuations. Commonly used NLP software/suite (e.g., Spacy, Hugging Face, and, OpenNMT) supports empirical tokenization. In addition, stand-alone tokenizers (like Sentence Piece/Word Piece) include modules for empirical tokenization.
Model-based tokenization:
Empirical tokenization has limited use when language does not use space or other characters as delimiters. For example, the Japanese language does not use space to separate words. Model-based tokenizers play a pivotal role when the language does not use recurring delimiters or have a large vocabulary. As the name suggests, model-based tokenizers need a model that guides the tokenization process. A large corpus of text from the relevant language is typically used to build a model. The model produces vocabulary (a list of tokens/subwords) that do not carry a meaning to humans but are used as a reference to tokenize a new set of text.
Transfer learning-based NLP protocols use model-based tokenizers. SentencePiece is one of the most widely used, general-purpose tokenizers. It provides c++ libraries and python wrappers to build tokenization models and modules to encode/decode text using constructed models.
Conclusion
Tokenization constitutes a fundamental step in higher-level NLP tasks. Based upon the objective of the task, language to perform NLP task on, and downstream learning methods to build word vector and machine learning method, either empirical or model-driven tokenizers. Nucleati NLP suite uses empirical word-based tokenizers. Our efficient and low-storage-fingerprint machine learning method is best suited for empirical, delimiter-based tokenization.
References:
- Tokenization [Article]
- How tokenizing text, sentence, words works [Article]
- SpaCy Tokenization [Documentation]